Comment améliorer les jeux d’open data ?
Alors qu’on invite les professionnels et les citoyens à s’emparer de l’open data, les jeux de data disponibles sont-ils vraiment de qualité et prêts-à-l’emploi ? J’ai pris un peu de temps pour répondre à cette question, qu’on m’a posée il y a une bonne semaine, afin de collecter quelques idées en plus des miennes sur Linkedin – merci à ceux qui ont commenté ce post.
Une open data de qualité, c’est d’abord une data FAIR
Findable, Accessible, Interoperable and Reusable – soit en français « Faciles à trouver, Accessibles, Interopérables et Réutilisables », voici les 4 qualificatifs d’une data de qualité depuis les travaux d’un groupe de travail international en 2014, auxquels il faut rajouter le mot « fair » (équitable) en lui-même pour ajouter la dimension altruiste et bénéfique de ce partage de données de qualité. Passons ces qualificatifs en revue afin de voir si l’open data française en est dotée actuellement :
Des données faciles à trouver
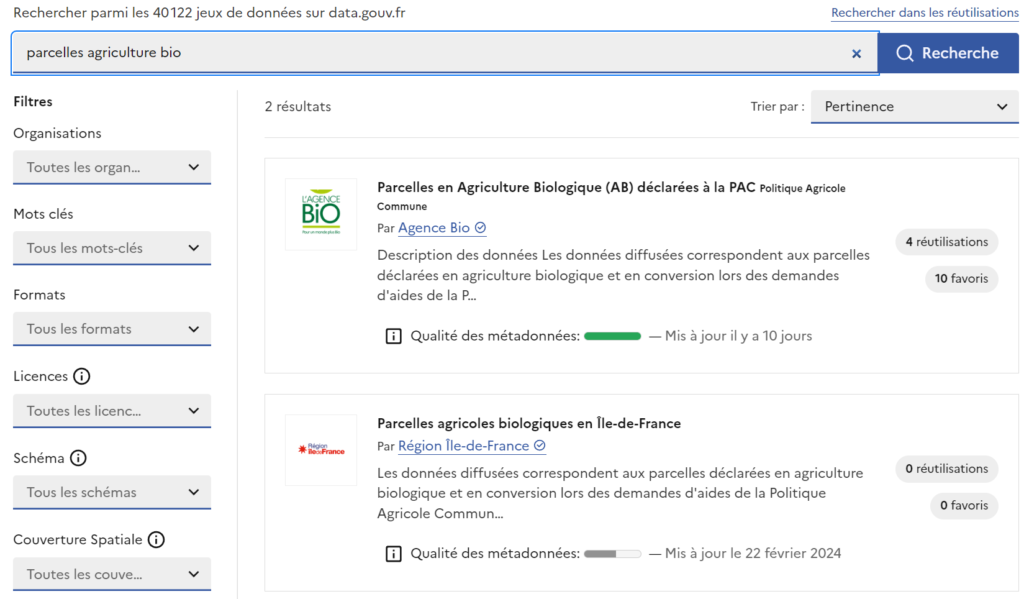
Quiconque a déjà manipulé un peu des données sait qu’il faut absolument 2 choses pour s’y retrouver dans les méandres des datasets qu’on peut trouver et être amené.e à croiser entre eux : un identificateur unique (le fameux ID) et des métadonnées bien claires qui permettront de chercher dans un moteur de site « parcelles agriculture bio » pour trouver le jeu de données qui en parle.
Testons tout de suite cette recherche sur le site data.gouv.fr : parfait, j’ai bien 2 jeux de données qui me semblent bien inclure des informations sur les parcelles en agriculture biologique.
Mais allons un peu plus loin car l’un des reproches adressés par les utilisateurs est qu’il y a parfois des jeux de données sur plusieurs plateformes et portails différents, plus ou moins connus. Ici, je suis allée directement sur Opendata France mais testons depuis un moteur de recherche utilisé à 94% en France : Google (en ajoutant quand même « données » devant ma requête). Le premier résultat est bien le jeu de données de l’agence bio sur Opendata France, ok.
Testons maintenant avec une requête un peu plus complexe comme « données parcelles utilisant du glyphosate » : les données accessibles semblent se limiter aux quantités de glyphosate vendues en France mais surtout, le premier site n’est pas Opendata France mais notre-environnement.gouv.fr, suivi d’une étude pdf sur les utilisations du glyphosate en agriculture dans les pays européens, suivi de nouveau par les ventes sur ecologie.gouv.fr, et beaucoup plus loin on trouve enfin un jeu de données sur Opendata France sur les exploitations engagées dans la réduction de glyphosate (a priori réalisé par un citoyen) avec une mention « données extraites du site web glyphosate.gouv.fr » sauf que ce site n’existe plus depuis 2021 (vérification sur WaybackMachine) alors que la dernière mise à jour du jeu semble dater du 30 mars 2024… Vous voyez à quel genre d’enquête on doit se livrer avant de parvenir à retrouver plusieurs jeux de données pertinents depuis Google ? Et est-ce que quelqu’un peut me dire pourquoi on a 2 sites différents sur l’environnement en .gouv.fr ?
Bref, pour être vraiment facile à trouver, l’open data doit aussi être bien référencée. Et franchement, il n’y aurait pas un si grand travail que ça à faire, à l’aide d’une automatisation mots-clés + LLM (ChatGPT et compagnie), pour assortir chaque jeu de données d’un texte de 800 mots optimisé pour les moteurs (cf. référencement naturel, SEO).
Des données accessibles
L’open data fair devrait être accessible par tous et toutes, librement, sans entraves et j’ajouterais même de façon « complète » et non parcellaire. Cela implique par exemple de les distribuer sous une licence connue comme les licences Creative Commons, ou encore d’indiquer s’il y a eu ou non une sélection opérée avant de partager les données disponibles.
Si j’attire l’attention sur ce point, c’est que je me dis que les professionnels à qui l’on demande de libérer la donnée pourraient se dire « ça, ça ne va pas leur servir, je ne le mets pas dans mon jeu de données » alors qu’une donnée insignifiante pour les uns pourrait être de l’or pour d’autres. C’est donc une invitation à ne pas penser à la place de l’utilisateur, surtout quand celui-ci est aussi divers et quand on ne sait pas de quoi l’avenir sera fait (besoin de ces données dans un projet critique dans 10 ans ?).
De plus, il est évident que « toutes les données ne sont pas bonnes à libérer » (toutes les vérités ne sont pas bonnes à dire) en fonction des intérêts privés ou même gouvernementaux. Dans un souci de transparence, les jeux d’open data publics devraient donc bien indiquer quelles données disponibles n’ont pas été ajoutées aux jeux publiés (ce sera plus difficile d’exiger cela pour les jeux privés).

Un point qui me tient à coeur également : veiller à ne pas créer une fracture data entre les territoires. En effet, si je compare le nombre de stations mesurant la qualité de l’air à Paris à notre petite station installée dans un quartier peu passant de la Roche-sur-Yon, je crains que les données ne soient pas collectées de la même façon selon les endroits. Selon Benoit Ribon (qui parlait d’utilisabilité de la data dans sa thèse), la fracture data est sans doute déjà là mais elle pourrait être réduite voire disparaître si on combinait acculturation data des petites collectivités et un peu plus de moyens sur la table.
Enfin, il est indispensable de permettre un accès libre et facile aux plateformes d’open data, c’est-à-dire de ne pas exiger de création de compte, même à obtention immédiate, encore moins sujet à autorisation suite à délibération de quiconque. Et ce n’est pas encore le cas sur bon nombre de sites administratifs. Par exemple, si la consultation d’Opendata France se fait sans compte, librement, ce n’est pas le cas de data.vendee.fr, le site de l’open data du département 85, pour lequel j’ai dû faire une demande de création de compte le 20 février dernier, demande qui n’a été acceptée que le 12 mars suivant…
Des données interopérables
Que ce soit pour croiser des données ou pour les utiliser (dans une cartographie, une analyse, une appli via une API, etc.), il faut que les données soient cohérentes entre elles. Par exemple, il est indispensable de mesurer les mêmes choses partout : imaginez que la taille des parcelles bio soit mesurée en prenant en compte la taille indiquée au cadastre sur un jeu de données et la taille du bornage réalisé par l’agriculteur lui-même dans un autre jeu de données, rien ne serait comparable. De même, si certaines données sont collectées tous les jours dans un jeu et tous les mois dans un autre jeu, cela complique le traitement. Des informations sur les mesures ou indicateurs utilisés devraient toujours figurer dans les jeux de données pour qu’on sache de quoi on parle.
De même, si les jeux de données sont publiés sous des formats de fichiers très différents, cela rendra très difficile leur croisement, d’où la nécessité d’utiliser de grands standards internationaux comme le .json et le .csv. On peut préciser que ces formats sont des standards acceptés par l’Internet Engineering Task Force et repris par l’ICANN (enfin, sa branche IANA Internet Assigned Numbers Authority). Ils ne sont donc pas « privés » comme peut l’être le format tableur Excel .xls ou .xlsx de Microsoft, ce qui préserve une certaine indépendance de format. De plus, ils sont utilisables avec relativement peu de connaissances techniques (surtout le CSV).
Or, en France, de ce que j’ai vu jusqu’ici, il y a beaucoup de jeux de données en csv et en json sur Opendata France et d’autres plateformes. En revanche, on en trouve encore beaucoup trop qui ne sont accessibles que dans des formats correspondant à des logiciels experts (ArcGIS par exemple) , ou des formats exotiques, ou enfermés dans des archives aux formats propriétaires comme le .7z, ou encore avec des poids de fichiers de plusieurs Go. On le voit assez rapidement d’ailleurs car ces plateformes-là sont rédigées dans un langage extrêmement technique et ne s’adressent clairement pas à un professionnel d’un autre métier ou à des particuliers curieux.
Enfin, il me semble important de ne pas « invisibiliser » la donnée en l’incorporant complètement au sein d’analyses prémâchées ou de cartographies sélectives. C’est un peu comme quand vous utilisez un outil no code comme Notion ou low-code comme WordPress : ce n’est pas parce que vous ne voyez pas le code de prime abord qu’il ne régit pas toutes les possibilités (et impossibilités) qui vous sont offertes. En open data, je tombe régulièrement sur des packs de données géographiques extrêmement lourds et difficiles à traiter dans des formats bizarres comme le .geojson alors que j’aurais préféré un simple CSV moins visuel mais plus facile à manipuler.
Des données réutilisables
Cela concerne normalement l’aspect réutilisable des données, notamment via des APIs, des exports, des exemples de réutilisations déjà réalisées à partir de ces jeux, de la fraîcheur ou du temps réel (qui va réutiliser un dataset ultra ponctuel jamais mis à jour depuis ?), mais aussi des informations sur les données en elles-mêmes, informations qui permettent de les comprendre et de les traiter.
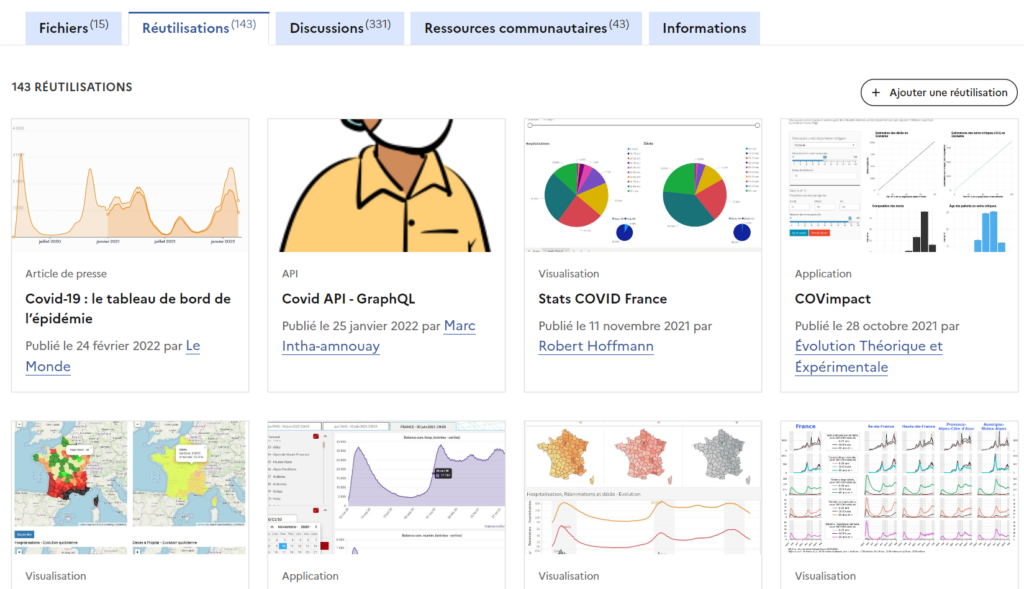
NB : Une idée pour Opendatasoft qui s’occupe de beaucoup de plateformes françaises et européennes : l’ajout d’un filtre dans l’encart « Réutilisations » serait une bonne idée pour qu’on puisse choisir le type de réutilisation qui nous intéresse (article de presse, visualisation, API, etc.), exemple ici avec les 143 réutilisations d’un dataset sur le covid-19.
C’est, selon moi, le point faible actuel de l’open data. On a obligé (légalement) de très nombreux organismes et administrations à publier rapidement toutes les données disponibles sur des plateformes comme Opendata France, souvent sans leur expliquer vraiment pourquoi, sans forcément leur diffuser une vraie culture data et sans prendre en compte l’objectif d’utilisabilité de la donnée (l’UX quoi). Typiquement, c’est l’histoire de cet article sur le jeu de données agrométéorologiques que j’ai décrypté il y a quelques semaines.
Impératif n°1 : Expliquer les données
Ce jeu de données ne contenait aucune description des en-têtes de colonne et on devait donc deviner à quoi correspondaient des acronymes tels que RR, TN, TX, FFM, TSVM… La réponse, je l’ai finalement trouvée sur Google en tapant « signification donnée FFM TSVM », ce qui m’a donné un lien vers le téléchargement direct d’un fichier CSV de donneespubliques.meteofrance.fr (même pas une page web, un fichier !). Pire, quelqu’un avait posé cette question dans l’onglet « Discussions », avait trouvé le CSV et avait répondu à sa propre question pour donner l’info, et personne n’a pris la peine d’ajouter cette info essentielle dans le descriptif.

De même, comprendre le sens des mesures réalisées sans comprendre le fonctionnement des appareils de collecte semblait impossible (quelle marge d’erreur, comment interpréter tel résultat, possibilité de faux-négatifs ou faux-positifs, nature des erreurs possibles, raison des données manquantes…) et a donc nécessité de nombreuses recherches supplémentaires. Pourquoi ? Parce que je ne suis pas météorologue de métier, je ne suis qu’un particulier cherchant à vérifier une ou deux hypothèses sur le climat vendéen en se basant sur des chiffres fiables. Quand vous allez dans l’aile égyptienne du Louvre, on ne vous demande pas de savoir déchiffrer les hiéroglyphes n’est-ce-pas ? On vous fournit des explications claires selon une trame de visite bien étudiée !
Impératif n°2 : Scénariser la donnée

Merci à Julien Dario d’avoir attiré mon attention sur cet enjeu (et d’autres). Tout comme au Louvre, vous avez votre livret ou votre appli ou votre casque de commentaire audio pour vous guider. Sur Opendata France, cela correspondrait à la description et à l’onglet « Informations » des jeux de données. Le moins qu’on puisse dire, c’est que tous les jeux de données ne sont pas expliqués de façon égale… J’imagine que si on avait pris un peu de temps pour co-construire les premiers jeux de données avec des utilisateurs, ils auraient conseillé, par exemple :
- une introduction expliquant dans quels scénarios cette donnée est utile
- une explication claire (mais vraiment claire, pas juste à quels mots correspondent les lettres d’un acronyme totalement inconnu) de toutes les en-têtes de colonne
- peut-être différentes granularités de données selon les besoins ou la possibilité de choisir les colonnes à ajouter (techniquement possible) pour ne pas être face à trop de données inutiles ou des fichiers trop lourds à traiter
- un guide d’interprétation des données pour bien comprendre comment et pourquoi elles ont été collectées, leurs limites, leur complétude ou non, etc.
Il n’est bien sûr pas trop tard et cela pourrait faire partie d’une grande initiative visant à valoriser ce travail déjà fait de mise à disposition. Quel service se sentirait satisfait d’avoir publié un jeu de données avec 0 réutilisation ? 3 étapes là aussi :
- expliquer l’intérêt d’améliorer l’utilisabilité des jeux de données (donc acculturer, citer des exemples forts, etc.),
- comprendre les obstacles (Dario parlait du silotage des données et du refus de perte de pouvoir sur les données entre certains services) et les lever,
- et surtout coconstruire avec les utilisateurs finaux en organisant des ateliers où on leur demande ce qu’ils voudraient faire avec ces datasets, ce qui leur manque, ce qui les bloque, etc. !
Impératif n°3 : Animer la donnée

C’est à David Huguet que je dois cette idée que la donnée doit être « animée ». Toujours en balade au Louvre, on apprécie d’avoir un guide vivant qui va nous apporter plein d’informations sur ce qu’on voit mais aussi des interprétations, des références croisées, des réflexions personnelles, etc. Et bien je pense comme David que les jeux d’open data devraient avoir un.e animateur.rice chargé d’éditorialiser et d’acculturer le public au contenu de son dataset. J’imagine que ces personnes, choisies dans les services fournisseurs de données, pourraient être des passionnés dont le travail et les connaissances seraient ainsi valorisés. Cela se rapproche de la notion de « data product owner » que j’ai croisée dans des travaux sur la data plutôt privée, d’entreprise quoi.
On pourrait imaginer différents supports à cette animation des jeux de données :
- un simple commentaire dans le dataset où il/elle pourrait expliquer l’intention et les possibilités des données mises à disposition
- une Foire Aux Questions où il/elle répond (rapidement et de façon extensive) aux interrogations des utilisateurs et s’en nourrit pour mettre à jour les informations du jeu de données
- une vidéo d’introduction au jeu de données et des vidéos complémentaires lors de mises à jour importantes ou pour commenter des réutilisations
- et pourquoi pas bientôt un agent conversationnel LLM permettant aux utilisateurs de discuter avec le jeu de données, entraîné par l’animateur.rice bien sûr
- le tout s’inscrivant dans une vraie politique d’éditorialisation du service (blog, réseaux sociaux, événements type hackathons ou ateliers de co-construction…)
Tout ceci permettrait de garantir une hausse ou un maintien de l’utilisabilité dans le temps, un accroissement de l’intérêt du public et des professionnels d’autres services/métiers, d’où une augmentation très probable des réutilisations.
Ce qu’en pensent les utilisateurs pros de data
Je suis tombée par hasard sur une « étude sur les usages, difficultés et besoins des utilisateurs dans la recherche, la production et l’utilisation de données ouvertes » il y a quelques jours. L’analyse des 131 réponses au questionnaire ainsi que des problèmes discutés en ateliers semble corroborer les observations ci-dessus (le public répondant faisant majoritairement partie des services déconcentrés de l’Etat, des administrations centrales, des université, de la recherche et des collectivités territoriales). Le domaine d’open data concerné était celui de l’environnement pour le pilotage de l’action publique.
Quelques enseignements de cette étude :
- 2/3 des répondants recherchent de l’open data plusieurs fois par mois pour leur travail
- 43,6% recherchent dans un catalogue en ligne, 37,8% via les moteurs de recherche Google, etc.
- De 1 – Aucune difficulté à 5 – Beaucoup de difficulté, la majorité éprouve des difficultés de 3 à 5 à rechercher/trouver de la donnée avec une note moyenne de 3,2, et une moyenne de 3,1 pour utiliser cette donnée.
- Les principales difficultés énoncées sont :
- Comprendre que la donnée peut être utile pour mon projet (acculturation)
- Savoir quelle donnée chercher pour mener à bien mon étude (valeur d’usage)
- Savoir où chercher les données dont j’ai besoin et trouver les bonnes données
- Etre sûr que les données utilisées sont fiables (qualité des données)
- Rendre mon utilisation des données utile à d’autres (réplicabilité)
- Et j’ai retenu quelques verbatim très intéressants :
- “Arrêter le foisonnement des plateformes de diffusion ou les obliger au moissonnage par une unique plateforme nationale.”
- “Ça reste une affaire de spécialistes. Un peu de vulgarisation vidéo serait utile.”
- “Elles ne sont pas « écrites » et « décrites » toujours de la même façon, il manque un standard sur les métadonnées.”
Conclusion – une marge de progression excitante
La Loi pour une République Numérique ne date finalement que de 2016 et les efforts de libération de la donnée publique ont été réels et très importants. Nous disposons de plateformes plutôt performantes malgré les quelques défauts relevés plus haut. Au niveau européen, la France se place au 1er rang de l’Open Data Maturity Report et 2ème au niveau mondial (source) ! Donc cocorico, sans aucun doute.
Il ne faut pas s’arrêter en si bon chemin ! L’open data est un outil précieux au service de la lutte contre le réchauffement climatique, de meilleures politiques publiques et des initiatives citoyennes. Alors acculturons producteurs et utilisateurs de données, rendons-la accessible en temps réel toutes les fois où c’est techniquement possible (notamment pour accompagner le développement de l’IoT), enrichissons les jeux de données, scénarisons-les, animons-les pour faire exploser le nombre de réutilisations, de recherches et de solutions trouvées grâce à l’open data !